
Version: v2.0
Input
Output
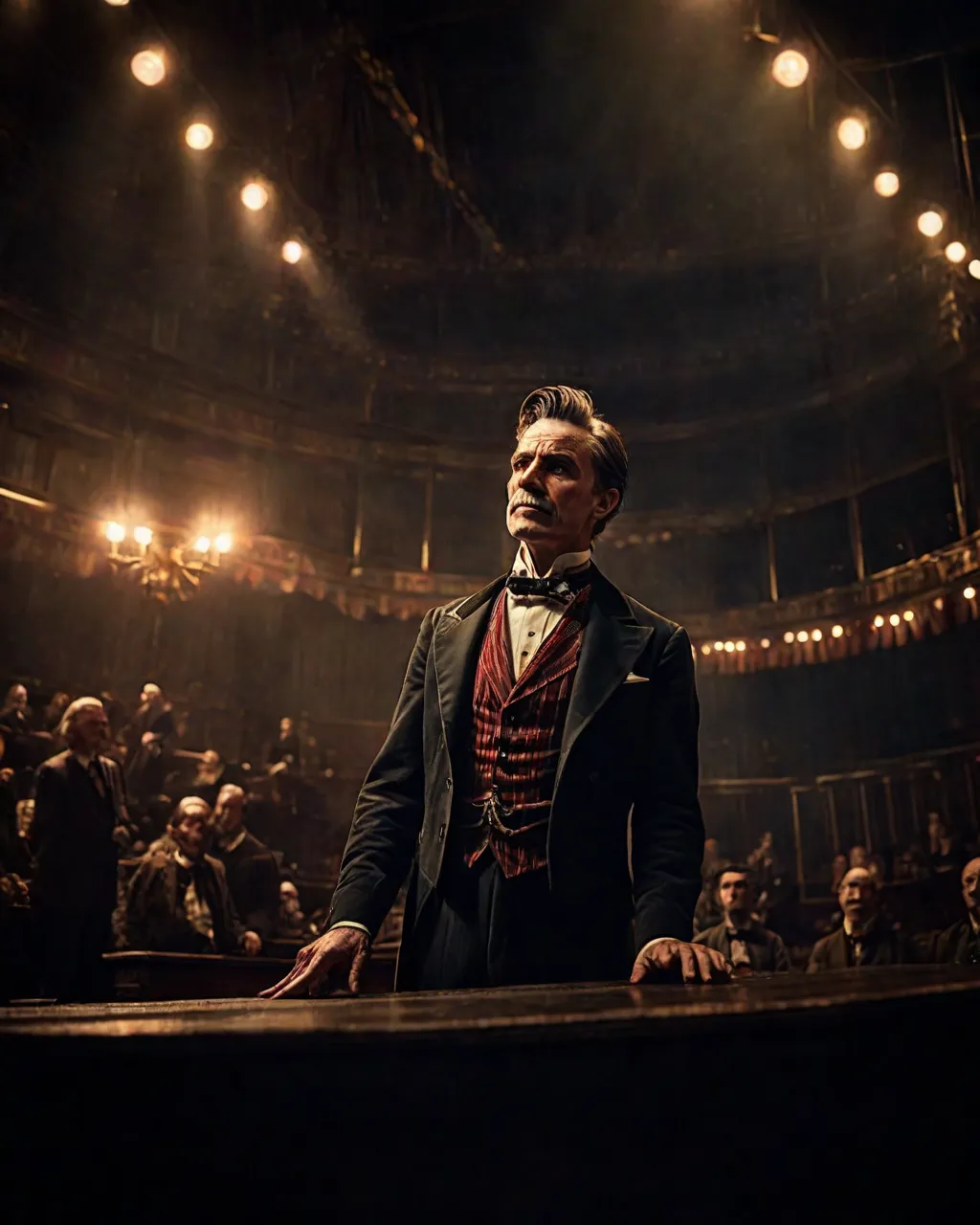
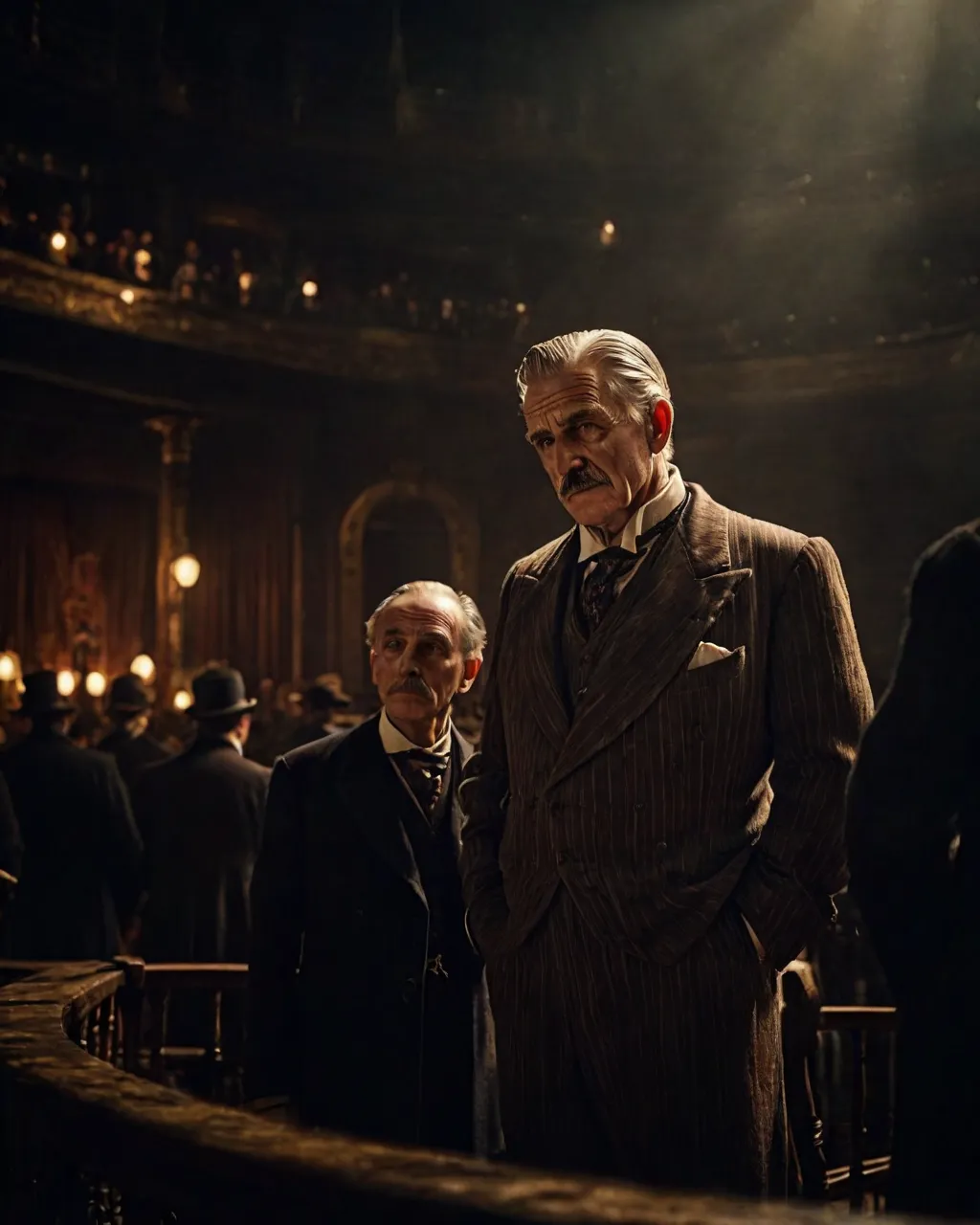

This example was created by sparks
Finished in 43.3 seconds
Setting up the model...
Preparing inputs...
Processing...
Loading VAE weight: models/VAE/sdxl_vae.safetensors
Full prompt: awesomize, cinematic film still, old circus director, Victorian London, amazing details, dark atmosphere, shallow depth of field, vignette, highly detailed, high budget, cinemascope, moody, epic, gorgeous, film, Fujichrome Provia 100F, F/8, RTX, photolab, high quality photography, 3 point lighting, flash with softbox, 4k, Canon EOS R3, hdr, smooth, sharp focus, high resolution, award winning photo, 80mm, f2.8, bokeh, <lora:EnvyBetterHiresFixXL01:0.5>, <lora:EnvyAwesomizeXL01:2>, <lora:add-detail-xl:1.0>
Full negative prompt: worst quality
0%| | 0/6 [00:00<?, ?it/s]
17%|█▋ | 1/6 [00:06<00:32, 6.52s/it]
33%|███▎ | 2/6 [00:13<00:27, 6.78s/it]
50%|█████ | 3/6 [00:20<00:20, 6.72s/it]
67%|██████▋ | 4/6 [00:26<00:13, 6.64s/it]
83%|████████▎ | 5/6 [00:31<00:05, 5.94s/it]
100%|██████████| 6/6 [00:32<00:00, 4.43s/it]
100%|██████████| 6/6 [00:32<00:00, 5.47s/it]
Decoding latents in cuda:0...
done in 3.01s
Move latents to cpu...
done in 0.04s
Uploading outputs...
Finished.
This example was created by sparks
Finished in 43.3 seconds
Setting up the model...
Preparing inputs...
Processing...
Loading VAE weight: models/VAE/sdxl_vae.safetensors
Full prompt: awesomize, cinematic film still, old circus director, Victorian London, amazing details, dark atmosphere, shallow depth of field, vignette, highly detailed, high budget, cinemascope, moody, epic, gorgeous, film, Fujichrome Provia 100F, F/8, RTX, photolab, high quality photography, 3 point lighting, flash with softbox, 4k, Canon EOS R3, hdr, smooth, sharp focus, high resolution, award winning photo, 80mm, f2.8, bokeh, <lora:EnvyBetterHiresFixXL01:0.5>, <lora:EnvyAwesomizeXL01:2>, <lora:add-detail-xl:1.0>
Full negative prompt: worst quality
0%| | 0/6 [00:00<?, ?it/s]
17%|█▋ | 1/6 [00:06<00:32, 6.52s/it]
33%|███▎ | 2/6 [00:13<00:27, 6.78s/it]
50%|█████ | 3/6 [00:20<00:20, 6.72s/it]
67%|██████▋ | 4/6 [00:26<00:13, 6.64s/it]
83%|████████▎ | 5/6 [00:31<00:05, 5.94s/it]
100%|██████████| 6/6 [00:32<00:00, 4.43s/it]
100%|██████████| 6/6 [00:32<00:00, 5.47s/it]
Decoding latents in cuda:0...
done in 3.01s
Move latents to cpu...
done in 0.04s
Uploading outputs...
Finished.