
Version: v2.0
Input
Output

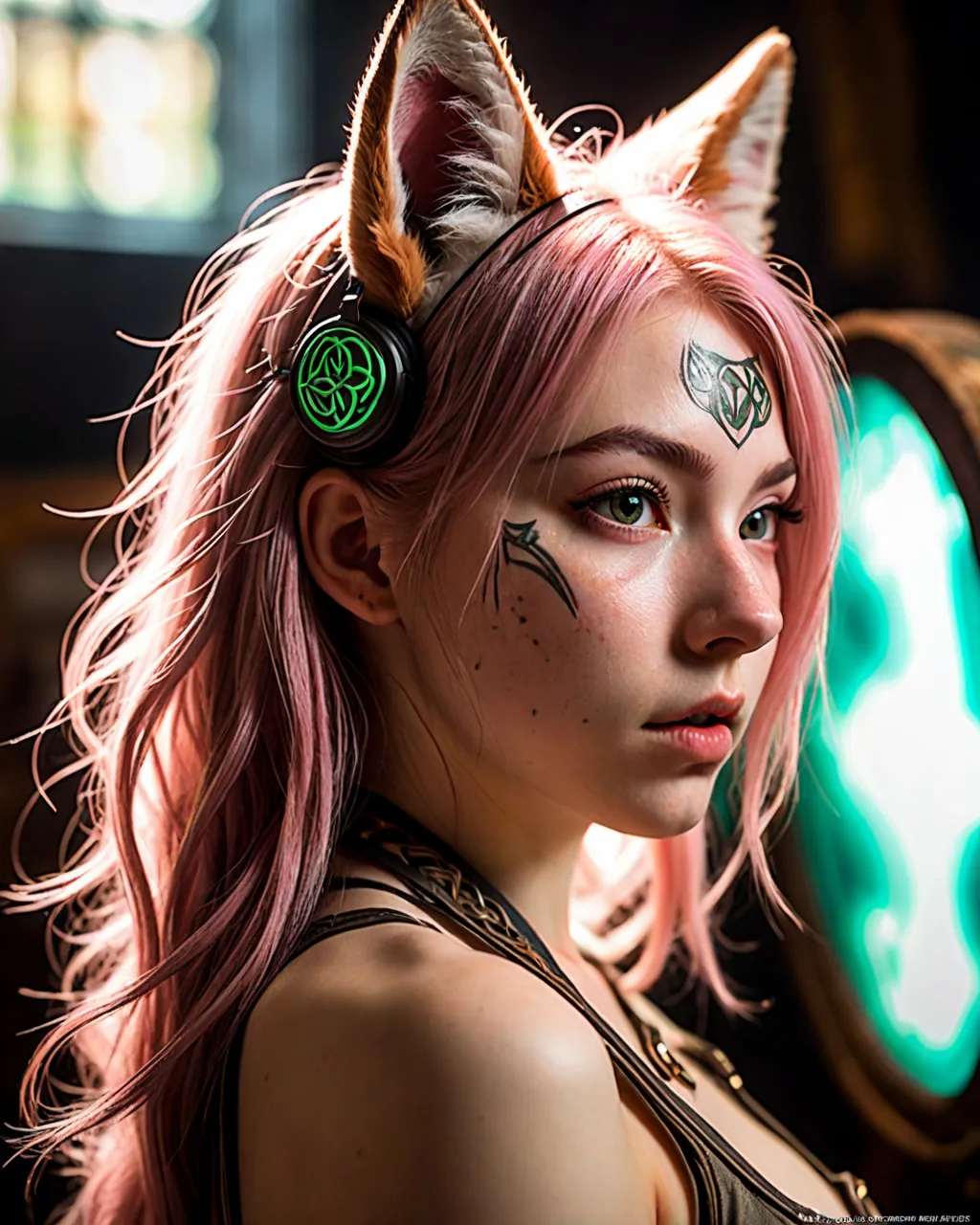

This example was created by sparks
Finished in 49.7 seconds
Setting up the model...
Preparing inputs...
Processing...
Loading VAE weight: models/VAE/sdxl_vae.safetensors
Full prompt: awesomize, art by gaston bussiere and alphonse mucha, photograph, highly detailed, over the shoulder shot of a Cruel Celtic (young woman, fox ears, skimpy:1.1), 20yo, Pink hair, inside of a Balanced Palenque, deep focus, Happy, side light, double exposure, Nikon d850, F/8, Cathode tube, <lora:EnvyBetterHiresFixXL01:0.5>, <lora:EnvyAwesomizeXL01:0.8>, <lora:add-detail-xl:1.0>
Full negative prompt:
0%| | 0/7 [00:00<?, ?it/s]
14%|█▍ | 1/7 [00:06<00:40, 6.79s/it]
29%|██▊ | 2/7 [00:13<00:34, 6.96s/it]
43%|████▎ | 3/7 [00:20<00:27, 6.87s/it]
57%|█████▋ | 4/7 [00:26<00:18, 6.28s/it]
71%|███████▏ | 5/7 [00:32<00:12, 6.21s/it]
86%|████████▌ | 6/7 [00:36<00:05, 5.73s/it]
100%|██████████| 7/7 [00:38<00:00, 4.37s/it]
100%|██████████| 7/7 [00:38<00:00, 5.50s/it]
Decoding latents in cuda:0...
done in 3.05s
Move latents to cpu...
done in 0.04s
Uploading outputs...
Finished.
This example was created by sparks
Finished in 49.7 seconds
Setting up the model...
Preparing inputs...
Processing...
Loading VAE weight: models/VAE/sdxl_vae.safetensors
Full prompt: awesomize, art by gaston bussiere and alphonse mucha, photograph, highly detailed, over the shoulder shot of a Cruel Celtic (young woman, fox ears, skimpy:1.1), 20yo, Pink hair, inside of a Balanced Palenque, deep focus, Happy, side light, double exposure, Nikon d850, F/8, Cathode tube, <lora:EnvyBetterHiresFixXL01:0.5>, <lora:EnvyAwesomizeXL01:0.8>, <lora:add-detail-xl:1.0>
Full negative prompt:
0%| | 0/7 [00:00<?, ?it/s]
14%|█▍ | 1/7 [00:06<00:40, 6.79s/it]
29%|██▊ | 2/7 [00:13<00:34, 6.96s/it]
43%|████▎ | 3/7 [00:20<00:27, 6.87s/it]
57%|█████▋ | 4/7 [00:26<00:18, 6.28s/it]
71%|███████▏ | 5/7 [00:32<00:12, 6.21s/it]
86%|████████▌ | 6/7 [00:36<00:05, 5.73s/it]
100%|██████████| 7/7 [00:38<00:00, 4.37s/it]
100%|██████████| 7/7 [00:38<00:00, 5.50s/it]
Decoding latents in cuda:0...
done in 3.05s
Move latents to cpu...
done in 0.04s
Uploading outputs...
Finished.