
Version: v1.0
Input
Output
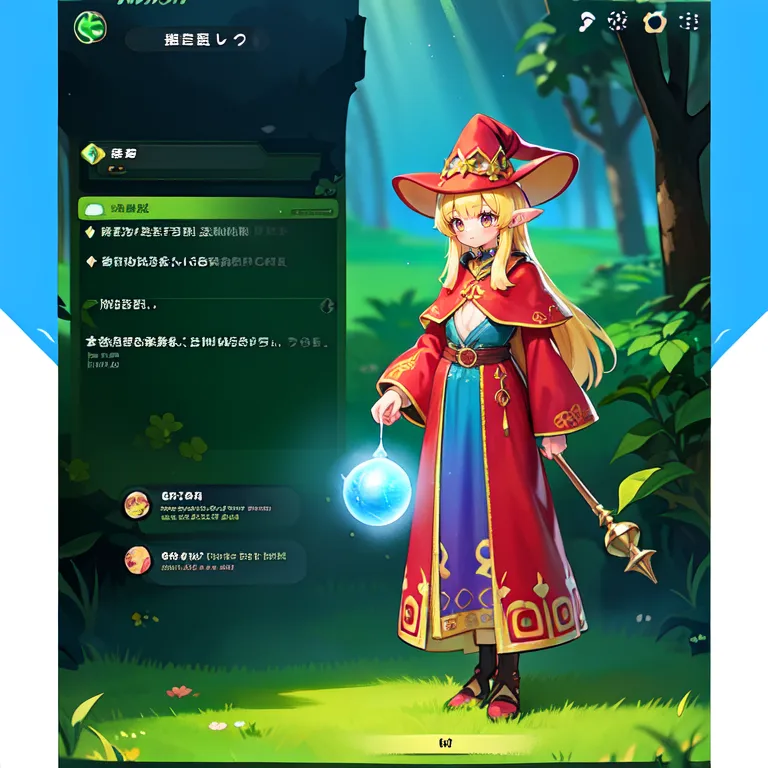
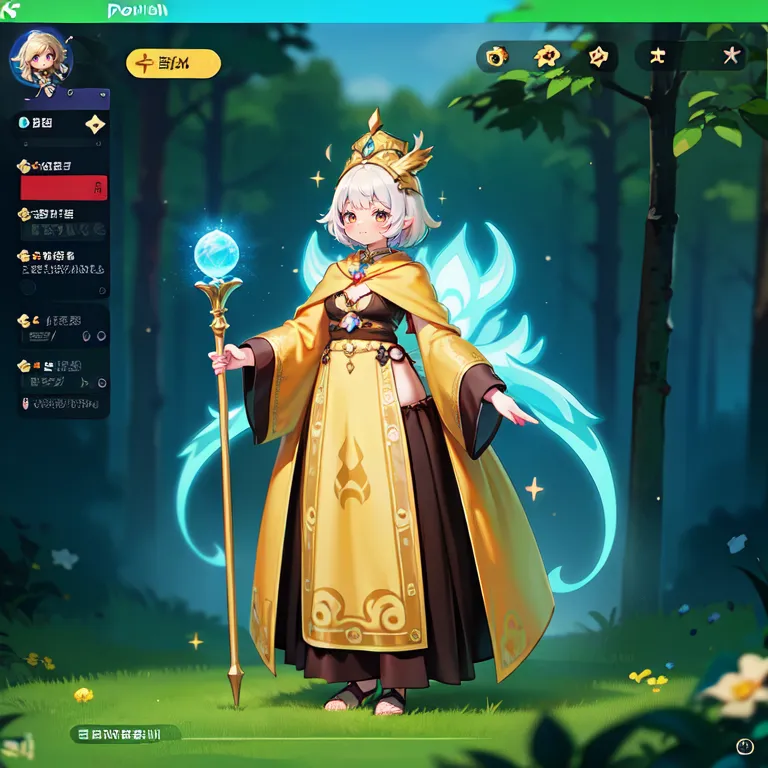
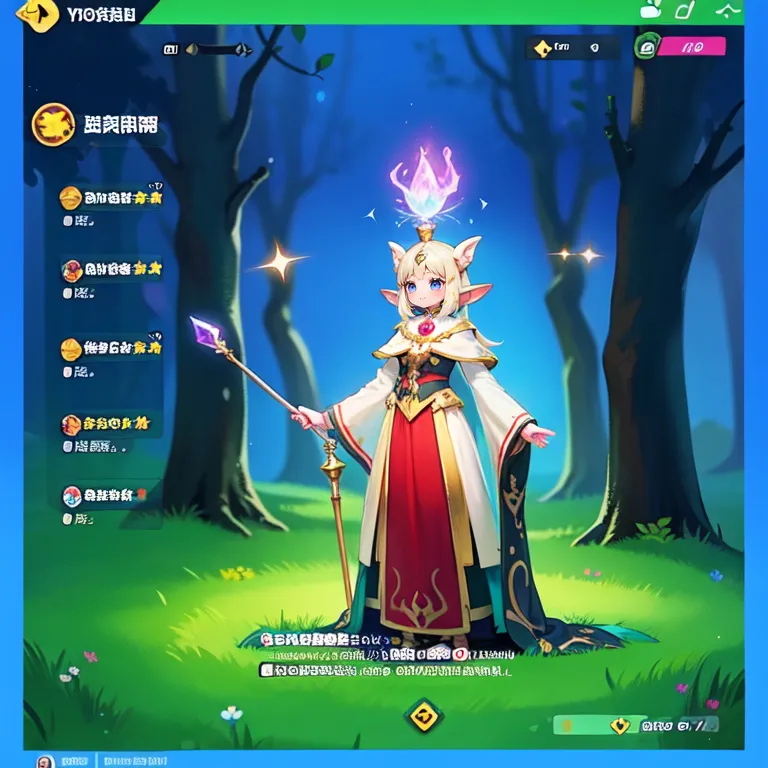
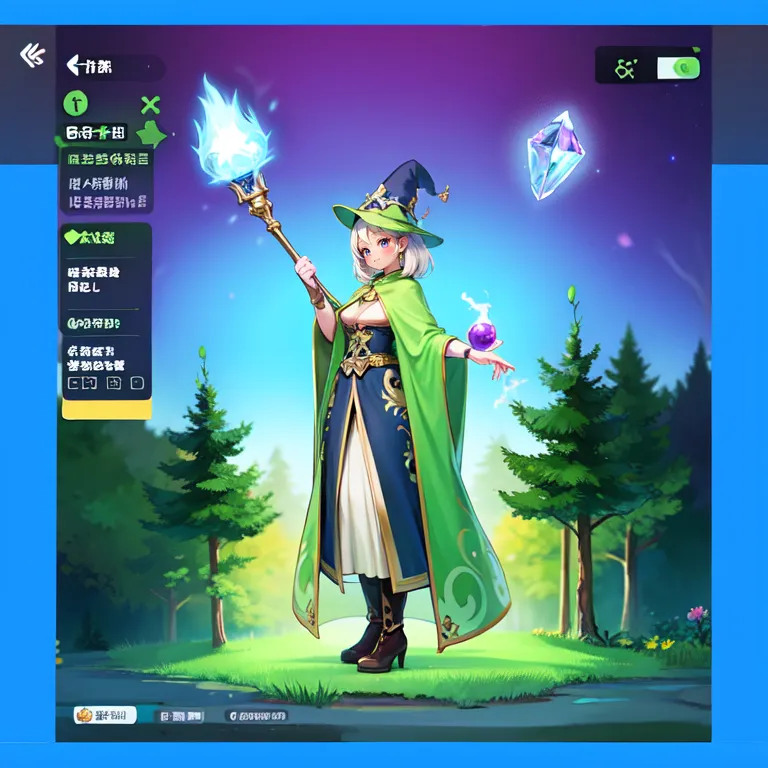
This example was created by evevalentine2017
Finished in 36.7 seconds
Setting up the model...
Preparing inputs...
Processing...
Loading VAE weight: models/VAE/kl-f8-anime2_fp16.safetensors
Full prompt: (masterpiece, top quality, best quality, official art, beautiful and aesthetic:1.2), a mystical forest scene, computer screen, within the enchanted grove, a woman stands, holding a staff and a crystal orb. She embodies the concept of attack, a solo 1girl channeling magical energies. Clad in an elven robe and hat, she radiates an aura of ancient wisdom amidst the medieval_age backdrop. This fake_screenshot captures her conjuring sparks of arcane power, her magic-infused attire resonating with the energies of the forest.
Full negative prompt: ((wrong fingers, extra feet, extra hands)),(worst quality:2), (low quality:2), (normal quality:2), lowres, normal quality, ((monochrome)), ((grayscale)), skin spots, acnes, skin blemishes, age spot, glans,extra fingers,fewer fingers,strange fingers,bad hand, badhandv4
0%| | 0/20 [00:00<?, ?it/s]
5%|▌ | 1/20 [00:00<00:13, 1.45it/s]
10%|█ | 2/20 [00:01<00:12, 1.49it/s]
15%|█▌ | 3/20 [00:01<00:11, 1.52it/s]
20%|██ | 4/20 [00:02<00:10, 1.54it/s]
25%|██▌ | 5/20 [00:03<00:09, 1.55it/s]
30%|███ | 6/20 [00:03<00:08, 1.56it/s]
35%|███▌ | 7/20 [00:04<00:08, 1.56it/s]
40%|████ | 8/20 [00:05<00:07, 1.56it/s]
45%|████▌ | 9/20 [00:05<00:07, 1.56it/s]
50%|█████ | 10/20 [00:06<00:06, 1.55it/s]
55%|█████▌ | 11/20 [00:07<00:05, 1.55it/s]
60%|██████ | 12/20 [00:07<00:05, 1.56it/s]
65%|██████▌ | 13/20 [00:08<00:04, 1.55it/s]
70%|███████ | 14/20 [00:09<00:03, 1.55it/s]
75%|███████▌ | 15/20 [00:09<00:03, 1.55it/s]
80%|████████ | 16/20 [00:10<00:02, 1.55it/s]
85%|████████▌ | 17/20 [00:10<00:01, 1.55it/s]
90%|█████████ | 18/20 [00:11<00:01, 1.55it/s]
95%|█████████▌| 19/20 [00:12<00:00, 1.53it/s]
100%|██████████| 20/20 [00:12<00:00, 1.56it/s]
100%|██████████| 20/20 [00:12<00:00, 1.55it/s]
Decoding latents in cuda:0...
done in 0.97s
Move latents to cpu...
done in 0.02s
0: 640x640 1 face, 8.5ms
Speed: 3.8ms preprocess, 8.5ms inference, 32.1ms postprocess per image at shape (1, 3, 640, 640)
0%| | 0/10 [00:00<?, ?it/s]
10%|█ | 1/10 [00:00<00:03, 2.36it/s]
20%|██ | 2/10 [00:00<00:02, 3.41it/s]
30%|███ | 3/10 [00:00<00:01, 3.93it/s]
40%|████ | 4/10 [00:01<00:01, 4.25it/s]
50%|█████ | 5/10 [00:01<00:01, 4.42it/s]
60%|██████ | 6/10 [00:01<00:00, 4.42it/s]
70%|███████ | 7/10 [00:01<00:00, 4.59it/s]
80%|████████ | 8/10 [00:01<00:00, 4.68it/s]
90%|█████████ | 9/10 [00:02<00:00, 4.67it/s]
100%|██████████| 10/10 [00:02<00:00, 4.73it/s]
100%|██████████| 10/10 [00:02<00:00, 4.34it/s]
Decoding latents in cuda:0...
done in 0.23s
Move latents to cpu...
done in 0.0s
0: 640x640 2 faces, 7.2ms
Speed: 2.7ms preprocess, 7.2ms inference, 2.1ms postprocess per image at shape (1, 3, 640, 640)
0%| | 0/10 [00:00<?, ?it/s]
10%|█ | 1/10 [00:00<00:02, 4.26it/s]
20%|██ | 2/10 [00:00<00:01, 4.57it/s]
30%|███ | 3/10 [00:00<00:01, 4.65it/s]
40%|████ | 4/10 [00:00<00:01, 4.77it/s]
50%|█████ | 5/10 [00:01<00:01, 4.64it/s]
60%|██████ | 6/10 [00:01<00:00, 4.69it/s]
70%|███████ | 7/10 [00:01<00:00, 4.74it/s]
80%|████████ | 8/10 [00:01<00:00, 4.80it/s]
90%|█████████ | 9/10 [00:01<00:00, 4.84it/s]
100%|██████████| 10/10 [00:02<00:00, 4.78it/s]
100%|██████████| 10/10 [00:02<00:00, 4.73it/s]
Decoding latents in cuda:0...
done in 0.24s
Move latents to cpu...
done in 0.0s
0%| | 0/10 [00:00<?, ?it/s]
10%|█ | 1/10 [00:00<00:01, 4.96it/s]
20%|██ | 2/10 [00:00<00:01, 4.91it/s]
30%|███ | 3/10 [00:00<00:01, 4.66it/s]
40%|████ | 4/10 [00:00<00:01, 4.61it/s]
50%|█████ | 5/10 [00:01<00:01, 4.72it/s]
60%|██████ | 6/10 [00:01<00:00, 4.68it/s]
70%|███████ | 7/10 [00:01<00:00, 4.64it/s]
80%|████████ | 8/10 [00:01<00:00, 4.69it/s]
90%|█████████ | 9/10 [00:01<00:00, 4.66it/s]
100%|██████████| 10/10 [00:02<00:00, 4.75it/s]
100%|██████████| 10/10 [00:02<00:00, 4.71it/s]
Decoding latents in cuda:0...
done in 0.23s
Move latents to cpu...
done in 0.0s
0: 640x640 1 face, 7.3ms
Speed: 2.9ms preprocess, 7.3ms inference, 1.6ms postprocess per image at shape (1, 3, 640, 640)
0%| | 0/10 [00:00<?, ?it/s]
10%|█ | 1/10 [00:00<00:01, 4.94it/s]
20%|██ | 2/10 [00:00<00:01, 4.93it/s]
30%|███ | 3/10 [00:00<00:01, 4.68it/s]
40%|████ | 4/10 [00:00<00:01, 4.78it/s]
50%|█████ | 5/10 [00:01<00:01, 4.60it/s]
60%|██████ | 6/10 [00:01<00:00, 4.50it/s]
70%|███████ | 7/10 [00:01<00:00, 4.36it/s]
80%|████████ | 8/10 [00:01<00:00, 4.43it/s]
90%|█████████ | 9/10 [00:01<00:00, 4.50it/s]
100%|██████████| 10/10 [00:02<00:00, 4.57it/s]
100%|██████████| 10/10 [00:02<00:00, 4.57it/s]
Decoding latents in cuda:0...
done in 0.24s
Move latents to cpu...
done in 0.0s
0: 640x640 1 face, 8.9ms
Speed: 3.0ms preprocess, 8.9ms inference, 1.8ms postprocess per image at shape (1, 3, 640, 640)
0%| | 0/10 [00:00<?, ?it/s]
10%|█ | 1/10 [00:00<00:02, 4.19it/s]
20%|██ | 2/10 [00:00<00:01, 4.42it/s]
30%|███ | 3/10 [00:00<00:01, 4.46it/s]
40%|████ | 4/10 [00:00<00:01, 4.48it/s]
50%|█████ | 5/10 [00:01<00:01, 4.45it/s]
60%|██████ | 6/10 [00:01<00:00, 4.47it/s]
70%|███████ | 7/10 [00:01<00:00, 4.61it/s]
80%|████████ | 8/10 [00:01<00:00, 4.71it/s]
90%|█████████ | 9/10 [00:01<00:00, 4.74it/s]
100%|██████████| 10/10 [00:02<00:00, 4.81it/s]
100%|██████████| 10/10 [00:02<00:00, 4.62it/s]
Decoding latents in cuda:0...
done in 0.24s
Move latents to cpu...
done in 0.0s
Uploading outputs...
Finished.
This example was created by evevalentine2017
Finished in 36.7 seconds
Setting up the model...
Preparing inputs...
Processing...
Loading VAE weight: models/VAE/kl-f8-anime2_fp16.safetensors
Full prompt: (masterpiece, top quality, best quality, official art, beautiful and aesthetic:1.2), a mystical forest scene, computer screen, within the enchanted grove, a woman stands, holding a staff and a crystal orb. She embodies the concept of attack, a solo 1girl channeling magical energies. Clad in an elven robe and hat, she radiates an aura of ancient wisdom amidst the medieval_age backdrop. This fake_screenshot captures her conjuring sparks of arcane power, her magic-infused attire resonating with the energies of the forest.
Full negative prompt: ((wrong fingers, extra feet, extra hands)),(worst quality:2), (low quality:2), (normal quality:2), lowres, normal quality, ((monochrome)), ((grayscale)), skin spots, acnes, skin blemishes, age spot, glans,extra fingers,fewer fingers,strange fingers,bad hand, badhandv4
0%| | 0/20 [00:00<?, ?it/s]
5%|▌ | 1/20 [00:00<00:13, 1.45it/s]
10%|█ | 2/20 [00:01<00:12, 1.49it/s]
15%|█▌ | 3/20 [00:01<00:11, 1.52it/s]
20%|██ | 4/20 [00:02<00:10, 1.54it/s]
25%|██▌ | 5/20 [00:03<00:09, 1.55it/s]
30%|███ | 6/20 [00:03<00:08, 1.56it/s]
35%|███▌ | 7/20 [00:04<00:08, 1.56it/s]
40%|████ | 8/20 [00:05<00:07, 1.56it/s]
45%|████▌ | 9/20 [00:05<00:07, 1.56it/s]
50%|█████ | 10/20 [00:06<00:06, 1.55it/s]
55%|█████▌ | 11/20 [00:07<00:05, 1.55it/s]
60%|██████ | 12/20 [00:07<00:05, 1.56it/s]
65%|██████▌ | 13/20 [00:08<00:04, 1.55it/s]
70%|███████ | 14/20 [00:09<00:03, 1.55it/s]
75%|███████▌ | 15/20 [00:09<00:03, 1.55it/s]
80%|████████ | 16/20 [00:10<00:02, 1.55it/s]
85%|████████▌ | 17/20 [00:10<00:01, 1.55it/s]
90%|█████████ | 18/20 [00:11<00:01, 1.55it/s]
95%|█████████▌| 19/20 [00:12<00:00, 1.53it/s]
100%|██████████| 20/20 [00:12<00:00, 1.56it/s]
100%|██████████| 20/20 [00:12<00:00, 1.55it/s]
Decoding latents in cuda:0...
done in 0.97s
Move latents to cpu...
done in 0.02s
0: 640x640 1 face, 8.5ms
Speed: 3.8ms preprocess, 8.5ms inference, 32.1ms postprocess per image at shape (1, 3, 640, 640)
0%| | 0/10 [00:00<?, ?it/s]
10%|█ | 1/10 [00:00<00:03, 2.36it/s]
20%|██ | 2/10 [00:00<00:02, 3.41it/s]
30%|███ | 3/10 [00:00<00:01, 3.93it/s]
40%|████ | 4/10 [00:01<00:01, 4.25it/s]
50%|█████ | 5/10 [00:01<00:01, 4.42it/s]
60%|██████ | 6/10 [00:01<00:00, 4.42it/s]
70%|███████ | 7/10 [00:01<00:00, 4.59it/s]
80%|████████ | 8/10 [00:01<00:00, 4.68it/s]
90%|█████████ | 9/10 [00:02<00:00, 4.67it/s]
100%|██████████| 10/10 [00:02<00:00, 4.73it/s]
100%|██████████| 10/10 [00:02<00:00, 4.34it/s]
Decoding latents in cuda:0...
done in 0.23s
Move latents to cpu...
done in 0.0s
0: 640x640 2 faces, 7.2ms
Speed: 2.7ms preprocess, 7.2ms inference, 2.1ms postprocess per image at shape (1, 3, 640, 640)
0%| | 0/10 [00:00<?, ?it/s]
10%|█ | 1/10 [00:00<00:02, 4.26it/s]
20%|██ | 2/10 [00:00<00:01, 4.57it/s]
30%|███ | 3/10 [00:00<00:01, 4.65it/s]
40%|████ | 4/10 [00:00<00:01, 4.77it/s]
50%|█████ | 5/10 [00:01<00:01, 4.64it/s]
60%|██████ | 6/10 [00:01<00:00, 4.69it/s]
70%|███████ | 7/10 [00:01<00:00, 4.74it/s]
80%|████████ | 8/10 [00:01<00:00, 4.80it/s]
90%|█████████ | 9/10 [00:01<00:00, 4.84it/s]
100%|██████████| 10/10 [00:02<00:00, 4.78it/s]
100%|██████████| 10/10 [00:02<00:00, 4.73it/s]
Decoding latents in cuda:0...
done in 0.24s
Move latents to cpu...
done in 0.0s
0%| | 0/10 [00:00<?, ?it/s]
10%|█ | 1/10 [00:00<00:01, 4.96it/s]
20%|██ | 2/10 [00:00<00:01, 4.91it/s]
30%|███ | 3/10 [00:00<00:01, 4.66it/s]
40%|████ | 4/10 [00:00<00:01, 4.61it/s]
50%|█████ | 5/10 [00:01<00:01, 4.72it/s]
60%|██████ | 6/10 [00:01<00:00, 4.68it/s]
70%|███████ | 7/10 [00:01<00:00, 4.64it/s]
80%|████████ | 8/10 [00:01<00:00, 4.69it/s]
90%|█████████ | 9/10 [00:01<00:00, 4.66it/s]
100%|██████████| 10/10 [00:02<00:00, 4.75it/s]
100%|██████████| 10/10 [00:02<00:00, 4.71it/s]
Decoding latents in cuda:0...
done in 0.23s
Move latents to cpu...
done in 0.0s
0: 640x640 1 face, 7.3ms
Speed: 2.9ms preprocess, 7.3ms inference, 1.6ms postprocess per image at shape (1, 3, 640, 640)
0%| | 0/10 [00:00<?, ?it/s]
10%|█ | 1/10 [00:00<00:01, 4.94it/s]
20%|██ | 2/10 [00:00<00:01, 4.93it/s]
30%|███ | 3/10 [00:00<00:01, 4.68it/s]
40%|████ | 4/10 [00:00<00:01, 4.78it/s]
50%|█████ | 5/10 [00:01<00:01, 4.60it/s]
60%|██████ | 6/10 [00:01<00:00, 4.50it/s]
70%|███████ | 7/10 [00:01<00:00, 4.36it/s]
80%|████████ | 8/10 [00:01<00:00, 4.43it/s]
90%|█████████ | 9/10 [00:01<00:00, 4.50it/s]
100%|██████████| 10/10 [00:02<00:00, 4.57it/s]
100%|██████████| 10/10 [00:02<00:00, 4.57it/s]
Decoding latents in cuda:0...
done in 0.24s
Move latents to cpu...
done in 0.0s
0: 640x640 1 face, 8.9ms
Speed: 3.0ms preprocess, 8.9ms inference, 1.8ms postprocess per image at shape (1, 3, 640, 640)
0%| | 0/10 [00:00<?, ?it/s]
10%|█ | 1/10 [00:00<00:02, 4.19it/s]
20%|██ | 2/10 [00:00<00:01, 4.42it/s]
30%|███ | 3/10 [00:00<00:01, 4.46it/s]
40%|████ | 4/10 [00:00<00:01, 4.48it/s]
50%|█████ | 5/10 [00:01<00:01, 4.45it/s]
60%|██████ | 6/10 [00:01<00:00, 4.47it/s]
70%|███████ | 7/10 [00:01<00:00, 4.61it/s]
80%|████████ | 8/10 [00:01<00:00, 4.71it/s]
90%|█████████ | 9/10 [00:01<00:00, 4.74it/s]
100%|██████████| 10/10 [00:02<00:00, 4.81it/s]
100%|██████████| 10/10 [00:02<00:00, 4.62it/s]
Decoding latents in cuda:0...
done in 0.24s
Move latents to cpu...
done in 0.0s
Uploading outputs...
Finished.