
Version: v1.0
Input
Output
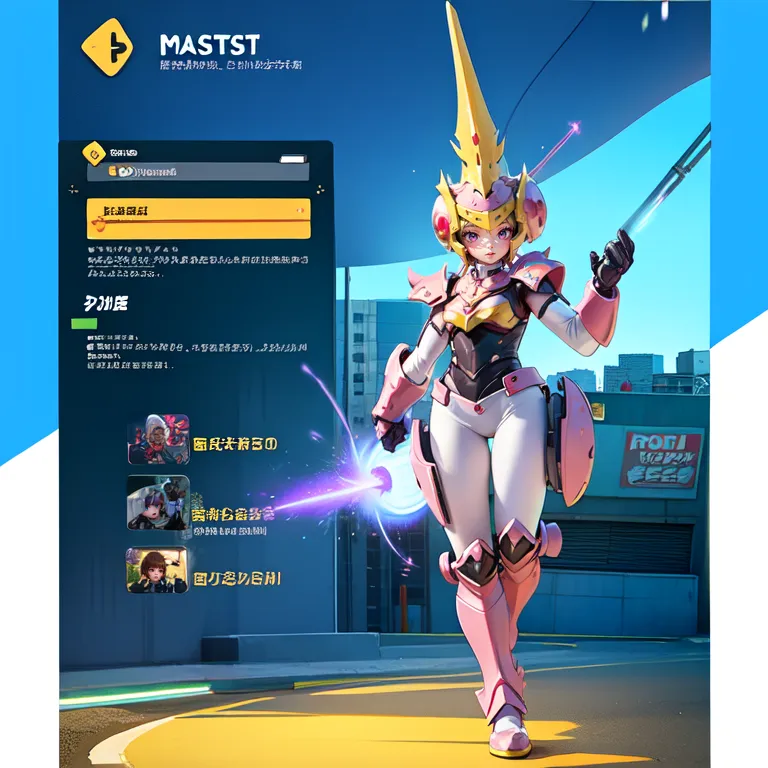
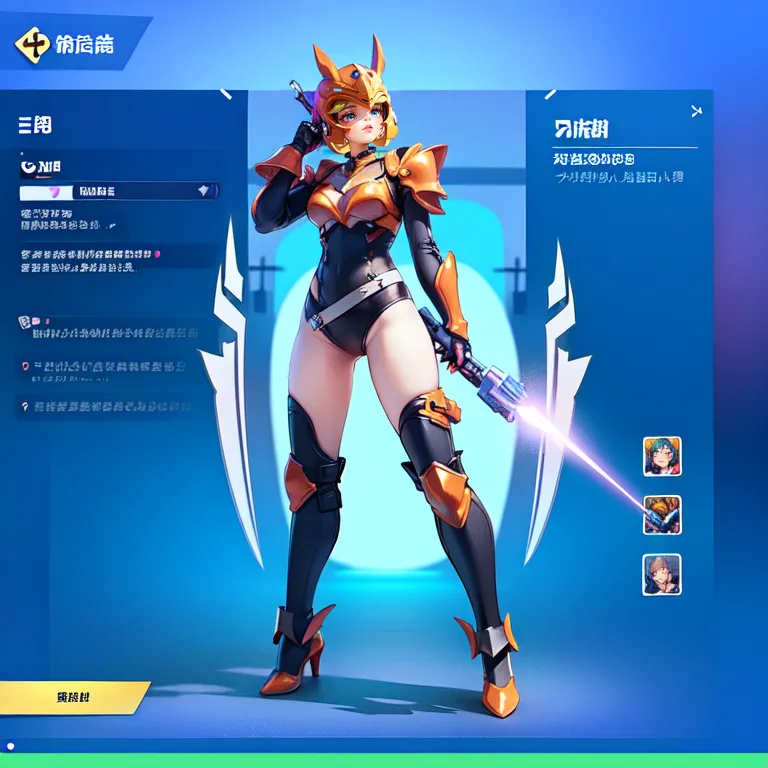
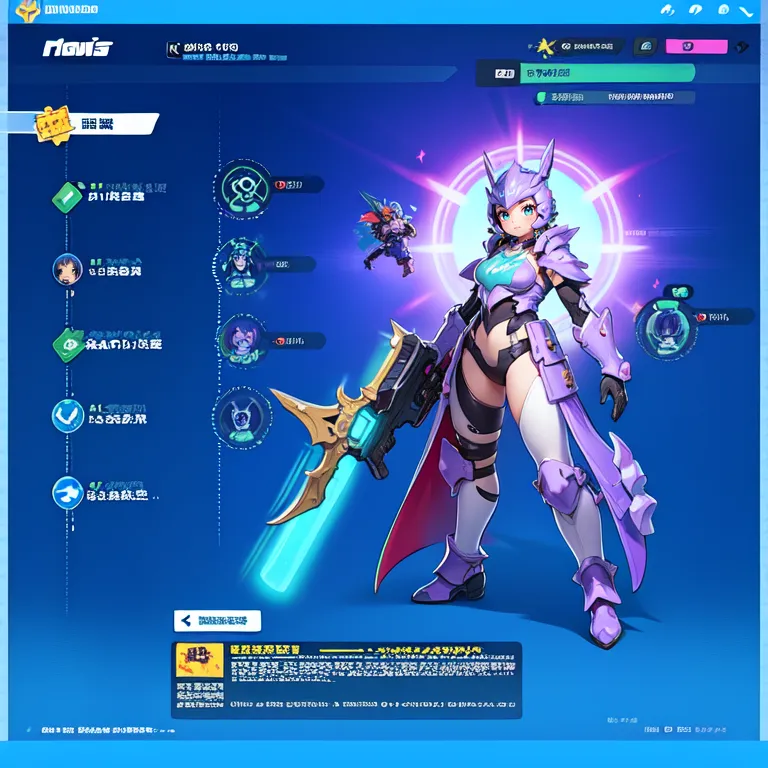
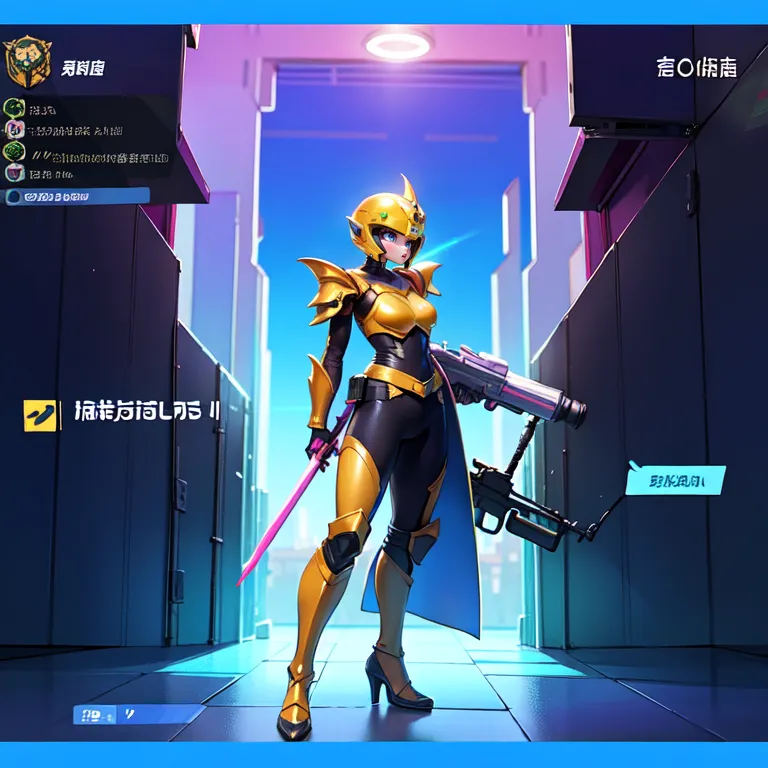
This example was created by evevalentine2017
Finished in 39.3 seconds
Setting up the model...
Preparing inputs...
Processing...
Loading VAE weight: models/VAE/kl-f8-anime2_fp16.safetensors
Full prompt: (masterpiece, top quality, best quality, official art, beautiful and aesthetic:1.2), computer screen, game menu, futuristic cityscape, a woman wielding a plasma sword and a laser pistol, embodying defense, solo, 1girl, holding, weapon, female_focus, holding_weapon, armor, helmet, high-tech, science fiction, fake_screenshot, power_outfit.
Full negative prompt: ((wrong fingers, extra feet, extra hands)),(worst quality:2), (low quality:2), (normal quality:2), lowres, normal quality, ((monochrome)), ((grayscale)), skin spots, acnes, skin blemishes, age spot, glans,extra fingers,fewer fingers,strange fingers,bad hand, badhandv4
0%| | 0/20 [00:00<?, ?it/s]
5%|▌ | 1/20 [00:00<00:13, 1.44it/s]
10%|█ | 2/20 [00:01<00:12, 1.49it/s]
15%|█▌ | 3/20 [00:01<00:11, 1.52it/s]
20%|██ | 4/20 [00:02<00:10, 1.52it/s]
25%|██▌ | 5/20 [00:03<00:09, 1.52it/s]
30%|███ | 6/20 [00:03<00:09, 1.52it/s]
35%|███▌ | 7/20 [00:04<00:08, 1.52it/s]
40%|████ | 8/20 [00:05<00:07, 1.52it/s]
45%|████▌ | 9/20 [00:05<00:07, 1.52it/s]
50%|█████ | 10/20 [00:06<00:06, 1.52it/s]
55%|█████▌ | 11/20 [00:07<00:05, 1.51it/s]
60%|██████ | 12/20 [00:07<00:05, 1.51it/s]
65%|██████▌ | 13/20 [00:08<00:04, 1.51it/s]
70%|███████ | 14/20 [00:09<00:03, 1.52it/s]
75%|███████▌ | 15/20 [00:09<00:03, 1.52it/s]
80%|████████ | 16/20 [00:10<00:02, 1.51it/s]
85%|████████▌ | 17/20 [00:11<00:01, 1.51it/s]
90%|█████████ | 18/20 [00:11<00:01, 1.51it/s]
95%|█████████▌| 19/20 [00:12<00:00, 1.51it/s]
100%|██████████| 20/20 [00:13<00:00, 1.52it/s]
100%|██████████| 20/20 [00:13<00:00, 1.51it/s]
Decoding latents in cuda:0...
done in 0.98s
Move latents to cpu...
done in 0.02s
0: 640x640 3 faces, 7.9ms
Speed: 3.8ms preprocess, 7.9ms inference, 31.2ms postprocess per image at shape (1, 3, 640, 640)
0%| | 0/10 [00:00<?, ?it/s]
10%|█ | 1/10 [00:00<00:03, 2.40it/s]
20%|██ | 2/10 [00:00<00:02, 3.40it/s]
30%|███ | 3/10 [00:00<00:01, 3.98it/s]
40%|████ | 4/10 [00:01<00:01, 4.29it/s]
50%|█████ | 5/10 [00:01<00:01, 4.26it/s]
60%|██████ | 6/10 [00:01<00:00, 4.46it/s]
70%|███████ | 7/10 [00:01<00:00, 4.59it/s]
80%|████████ | 8/10 [00:01<00:00, 4.70it/s]
90%|█████████ | 9/10 [00:02<00:00, 4.78it/s]
100%|██████████| 10/10 [00:02<00:00, 4.66it/s]
100%|██████████| 10/10 [00:02<00:00, 4.33it/s]
Decoding latents in cuda:0...
done in 0.24s
Move latents to cpu...
done in 0.0s
0%| | 0/10 [00:00<?, ?it/s]
10%|█ | 1/10 [00:00<00:01, 4.73it/s]
20%|██ | 2/10 [00:00<00:01, 4.52it/s]
30%|███ | 3/10 [00:00<00:01, 4.69it/s]
40%|████ | 4/10 [00:00<00:01, 4.75it/s]
50%|█████ | 5/10 [00:01<00:01, 4.80it/s]
60%|██████ | 6/10 [00:01<00:00, 4.84it/s]
70%|███████ | 7/10 [00:01<00:00, 4.73it/s]
80%|████████ | 8/10 [00:01<00:00, 4.65it/s]
90%|█████████ | 9/10 [00:01<00:00, 4.68it/s]
100%|██████████| 10/10 [00:02<00:00, 4.80it/s]
100%|██████████| 10/10 [00:02<00:00, 4.74it/s]
Decoding latents in cuda:0...
done in 0.24s
Move latents to cpu...
done in 0.0s
0%| | 0/10 [00:00<?, ?it/s]
10%|█ | 1/10 [00:00<00:01, 4.83it/s]
20%|██ | 2/10 [00:00<00:01, 4.84it/s]
30%|███ | 3/10 [00:00<00:01, 4.81it/s]
40%|████ | 4/10 [00:00<00:01, 4.83it/s]
50%|█████ | 5/10 [00:01<00:01, 4.86it/s]
60%|██████ | 6/10 [00:01<00:00, 4.91it/s]
70%|███████ | 7/10 [00:01<00:00, 4.88it/s]
80%|████████ | 8/10 [00:01<00:00, 4.88it/s]
90%|█████████ | 9/10 [00:01<00:00, 4.77it/s]
100%|██████████| 10/10 [00:02<00:00, 4.83it/s]
100%|██████████| 10/10 [00:02<00:00, 4.84it/s]
Decoding latents in cuda:0...
done in 0.24s
Move latents to cpu...
done in 0.0s
0: 640x640 1 face, 7.1ms
Speed: 2.7ms preprocess, 7.1ms inference, 1.5ms postprocess per image at shape (1, 3, 640, 640)
0%| | 0/10 [00:00<?, ?it/s]
10%|█ | 1/10 [00:00<00:01, 4.99it/s]
20%|██ | 2/10 [00:00<00:01, 4.94it/s]
30%|███ | 3/10 [00:00<00:01, 4.46it/s]
40%|████ | 4/10 [00:00<00:01, 4.36it/s]
50%|█████ | 5/10 [00:01<00:01, 4.51it/s]
60%|██████ | 6/10 [00:01<00:00, 4.64it/s]
70%|███████ | 7/10 [00:01<00:00, 4.73it/s]
80%|████████ | 8/10 [00:01<00:00, 4.78it/s]
90%|█████████ | 9/10 [00:01<00:00, 4.63it/s]
100%|██████████| 10/10 [00:02<00:00, 4.75it/s]
100%|██████████| 10/10 [00:02<00:00, 4.67it/s]
Decoding latents in cuda:0...
done in 0.25s
Move latents to cpu...
done in 0.0s
0: 640x640 1 face, 7.2ms
Speed: 2.6ms preprocess, 7.2ms inference, 1.4ms postprocess per image at shape (1, 3, 640, 640)
0%| | 0/10 [00:00<?, ?it/s]
10%|█ | 1/10 [00:00<00:01, 4.92it/s]
20%|██ | 2/10 [00:00<00:01, 4.92it/s]
30%|███ | 3/10 [00:00<00:01, 4.96it/s]
40%|████ | 4/10 [00:00<00:01, 4.79it/s]
50%|█████ | 5/10 [00:01<00:01, 4.76it/s]
60%|██████ | 6/10 [00:01<00:00, 4.74it/s]
70%|███████ | 7/10 [00:01<00:00, 4.82it/s]
80%|████████ | 8/10 [00:01<00:00, 4.85it/s]
90%|█████████ | 9/10 [00:01<00:00, 4.85it/s]
100%|██████████| 10/10 [00:02<00:00, 4.91it/s]
100%|██████████| 10/10 [00:02<00:00, 4.86it/s]
Decoding latents in cuda:0...
done in 0.24s
Move latents to cpu...
done in 0.0s
0: 640x640 1 face, 7.7ms
Speed: 2.8ms preprocess, 7.7ms inference, 1.4ms postprocess per image at shape (1, 3, 640, 640)
0%| | 0/10 [00:00<?, ?it/s]
10%|█ | 1/10 [00:00<00:01, 5.01it/s]
20%|██ | 2/10 [00:00<00:01, 4.97it/s]
30%|███ | 3/10 [00:00<00:01, 4.98it/s]
40%|████ | 4/10 [00:00<00:01, 5.00it/s]
50%|█████ | 5/10 [00:01<00:01, 4.63it/s]
60%|██████ | 6/10 [00:01<00:00, 4.71it/s]
70%|███████ | 7/10 [00:01<00:00, 4.76it/s]
80%|████████ | 8/10 [00:01<00:00, 4.80it/s]
90%|█████████ | 9/10 [00:01<00:00, 4.77it/s]
100%|██████████| 10/10 [00:02<00:00, 4.81it/s]
100%|██████████| 10/10 [00:02<00:00, 4.81it/s]
Decoding latents in cuda:0...
done in 0.25s
Move latents to cpu...
done in 0.0s
Uploading outputs...
Finished.
This example was created by evevalentine2017
Finished in 39.3 seconds
Setting up the model...
Preparing inputs...
Processing...
Loading VAE weight: models/VAE/kl-f8-anime2_fp16.safetensors
Full prompt: (masterpiece, top quality, best quality, official art, beautiful and aesthetic:1.2), computer screen, game menu, futuristic cityscape, a woman wielding a plasma sword and a laser pistol, embodying defense, solo, 1girl, holding, weapon, female_focus, holding_weapon, armor, helmet, high-tech, science fiction, fake_screenshot, power_outfit.
Full negative prompt: ((wrong fingers, extra feet, extra hands)),(worst quality:2), (low quality:2), (normal quality:2), lowres, normal quality, ((monochrome)), ((grayscale)), skin spots, acnes, skin blemishes, age spot, glans,extra fingers,fewer fingers,strange fingers,bad hand, badhandv4
0%| | 0/20 [00:00<?, ?it/s]
5%|▌ | 1/20 [00:00<00:13, 1.44it/s]
10%|█ | 2/20 [00:01<00:12, 1.49it/s]
15%|█▌ | 3/20 [00:01<00:11, 1.52it/s]
20%|██ | 4/20 [00:02<00:10, 1.52it/s]
25%|██▌ | 5/20 [00:03<00:09, 1.52it/s]
30%|███ | 6/20 [00:03<00:09, 1.52it/s]
35%|███▌ | 7/20 [00:04<00:08, 1.52it/s]
40%|████ | 8/20 [00:05<00:07, 1.52it/s]
45%|████▌ | 9/20 [00:05<00:07, 1.52it/s]
50%|█████ | 10/20 [00:06<00:06, 1.52it/s]
55%|█████▌ | 11/20 [00:07<00:05, 1.51it/s]
60%|██████ | 12/20 [00:07<00:05, 1.51it/s]
65%|██████▌ | 13/20 [00:08<00:04, 1.51it/s]
70%|███████ | 14/20 [00:09<00:03, 1.52it/s]
75%|███████▌ | 15/20 [00:09<00:03, 1.52it/s]
80%|████████ | 16/20 [00:10<00:02, 1.51it/s]
85%|████████▌ | 17/20 [00:11<00:01, 1.51it/s]
90%|█████████ | 18/20 [00:11<00:01, 1.51it/s]
95%|█████████▌| 19/20 [00:12<00:00, 1.51it/s]
100%|██████████| 20/20 [00:13<00:00, 1.52it/s]
100%|██████████| 20/20 [00:13<00:00, 1.51it/s]
Decoding latents in cuda:0...
done in 0.98s
Move latents to cpu...
done in 0.02s
0: 640x640 3 faces, 7.9ms
Speed: 3.8ms preprocess, 7.9ms inference, 31.2ms postprocess per image at shape (1, 3, 640, 640)
0%| | 0/10 [00:00<?, ?it/s]
10%|█ | 1/10 [00:00<00:03, 2.40it/s]
20%|██ | 2/10 [00:00<00:02, 3.40it/s]
30%|███ | 3/10 [00:00<00:01, 3.98it/s]
40%|████ | 4/10 [00:01<00:01, 4.29it/s]
50%|█████ | 5/10 [00:01<00:01, 4.26it/s]
60%|██████ | 6/10 [00:01<00:00, 4.46it/s]
70%|███████ | 7/10 [00:01<00:00, 4.59it/s]
80%|████████ | 8/10 [00:01<00:00, 4.70it/s]
90%|█████████ | 9/10 [00:02<00:00, 4.78it/s]
100%|██████████| 10/10 [00:02<00:00, 4.66it/s]
100%|██████████| 10/10 [00:02<00:00, 4.33it/s]
Decoding latents in cuda:0...
done in 0.24s
Move latents to cpu...
done in 0.0s
0%| | 0/10 [00:00<?, ?it/s]
10%|█ | 1/10 [00:00<00:01, 4.73it/s]
20%|██ | 2/10 [00:00<00:01, 4.52it/s]
30%|███ | 3/10 [00:00<00:01, 4.69it/s]
40%|████ | 4/10 [00:00<00:01, 4.75it/s]
50%|█████ | 5/10 [00:01<00:01, 4.80it/s]
60%|██████ | 6/10 [00:01<00:00, 4.84it/s]
70%|███████ | 7/10 [00:01<00:00, 4.73it/s]
80%|████████ | 8/10 [00:01<00:00, 4.65it/s]
90%|█████████ | 9/10 [00:01<00:00, 4.68it/s]
100%|██████████| 10/10 [00:02<00:00, 4.80it/s]
100%|██████████| 10/10 [00:02<00:00, 4.74it/s]
Decoding latents in cuda:0...
done in 0.24s
Move latents to cpu...
done in 0.0s
0%| | 0/10 [00:00<?, ?it/s]
10%|█ | 1/10 [00:00<00:01, 4.83it/s]
20%|██ | 2/10 [00:00<00:01, 4.84it/s]
30%|███ | 3/10 [00:00<00:01, 4.81it/s]
40%|████ | 4/10 [00:00<00:01, 4.83it/s]
50%|█████ | 5/10 [00:01<00:01, 4.86it/s]
60%|██████ | 6/10 [00:01<00:00, 4.91it/s]
70%|███████ | 7/10 [00:01<00:00, 4.88it/s]
80%|████████ | 8/10 [00:01<00:00, 4.88it/s]
90%|█████████ | 9/10 [00:01<00:00, 4.77it/s]
100%|██████████| 10/10 [00:02<00:00, 4.83it/s]
100%|██████████| 10/10 [00:02<00:00, 4.84it/s]
Decoding latents in cuda:0...
done in 0.24s
Move latents to cpu...
done in 0.0s
0: 640x640 1 face, 7.1ms
Speed: 2.7ms preprocess, 7.1ms inference, 1.5ms postprocess per image at shape (1, 3, 640, 640)
0%| | 0/10 [00:00<?, ?it/s]
10%|█ | 1/10 [00:00<00:01, 4.99it/s]
20%|██ | 2/10 [00:00<00:01, 4.94it/s]
30%|███ | 3/10 [00:00<00:01, 4.46it/s]
40%|████ | 4/10 [00:00<00:01, 4.36it/s]
50%|█████ | 5/10 [00:01<00:01, 4.51it/s]
60%|██████ | 6/10 [00:01<00:00, 4.64it/s]
70%|███████ | 7/10 [00:01<00:00, 4.73it/s]
80%|████████ | 8/10 [00:01<00:00, 4.78it/s]
90%|█████████ | 9/10 [00:01<00:00, 4.63it/s]
100%|██████████| 10/10 [00:02<00:00, 4.75it/s]
100%|██████████| 10/10 [00:02<00:00, 4.67it/s]
Decoding latents in cuda:0...
done in 0.25s
Move latents to cpu...
done in 0.0s
0: 640x640 1 face, 7.2ms
Speed: 2.6ms preprocess, 7.2ms inference, 1.4ms postprocess per image at shape (1, 3, 640, 640)
0%| | 0/10 [00:00<?, ?it/s]
10%|█ | 1/10 [00:00<00:01, 4.92it/s]
20%|██ | 2/10 [00:00<00:01, 4.92it/s]
30%|███ | 3/10 [00:00<00:01, 4.96it/s]
40%|████ | 4/10 [00:00<00:01, 4.79it/s]
50%|█████ | 5/10 [00:01<00:01, 4.76it/s]
60%|██████ | 6/10 [00:01<00:00, 4.74it/s]
70%|███████ | 7/10 [00:01<00:00, 4.82it/s]
80%|████████ | 8/10 [00:01<00:00, 4.85it/s]
90%|█████████ | 9/10 [00:01<00:00, 4.85it/s]
100%|██████████| 10/10 [00:02<00:00, 4.91it/s]
100%|██████████| 10/10 [00:02<00:00, 4.86it/s]
Decoding latents in cuda:0...
done in 0.24s
Move latents to cpu...
done in 0.0s
0: 640x640 1 face, 7.7ms
Speed: 2.8ms preprocess, 7.7ms inference, 1.4ms postprocess per image at shape (1, 3, 640, 640)
0%| | 0/10 [00:00<?, ?it/s]
10%|█ | 1/10 [00:00<00:01, 5.01it/s]
20%|██ | 2/10 [00:00<00:01, 4.97it/s]
30%|███ | 3/10 [00:00<00:01, 4.98it/s]
40%|████ | 4/10 [00:00<00:01, 5.00it/s]
50%|█████ | 5/10 [00:01<00:01, 4.63it/s]
60%|██████ | 6/10 [00:01<00:00, 4.71it/s]
70%|███████ | 7/10 [00:01<00:00, 4.76it/s]
80%|████████ | 8/10 [00:01<00:00, 4.80it/s]
90%|█████████ | 9/10 [00:01<00:00, 4.77it/s]
100%|██████████| 10/10 [00:02<00:00, 4.81it/s]
100%|██████████| 10/10 [00:02<00:00, 4.81it/s]
Decoding latents in cuda:0...
done in 0.25s
Move latents to cpu...
done in 0.0s
Uploading outputs...
Finished.