
Version: lightning
Input
Output


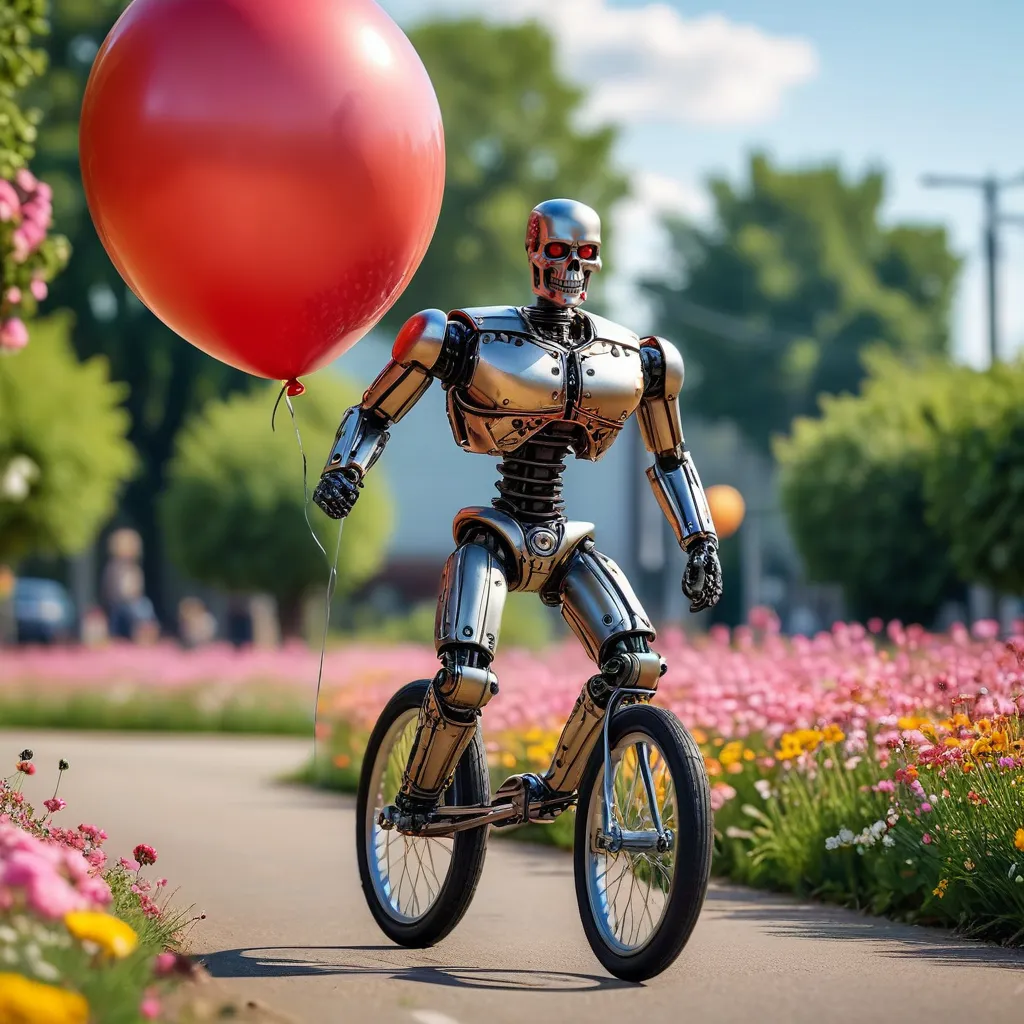
This example was created by evevalentine2017
Finished in 49.6 seconds
Setting up the model...
Preparing inputs...
Processing...
Full prompt: photograph, funny, the terminator in tutu looking at viewer, riding on a unicycle holding a big balloon made of flowers, stunning details, 8k, raw photo, 8k uhd, film grain, unreal engine 5, ray tracing, dynamic, Nikon d850, Depth of field 270mm, Amaro, Golden ratio, <lora:TLS:0.5>
Full negative prompt: CGI, Unreal, Airbrushed, Digital, dark, oversaturated, humans
0%| | 0/5 [00:00<?, ?it/s]
20%|██ | 1/5 [00:05<00:21, 5.36s/it]
40%|████ | 2/5 [00:10<00:16, 5.33s/it]
60%|██████ | 3/5 [00:15<00:10, 5.30s/it]
80%|████████ | 4/5 [00:19<00:04, 4.78s/it]
100%|██████████| 5/5 [00:21<00:00, 3.54s/it]
100%|██████████| 5/5 [00:21<00:00, 4.25s/it]
Decoding latents in cuda:0...
done in 2.39s
Move latents to cpu...
done in 0.03s
0: 640x640 1 face, 7.9ms
Speed: 3.8ms preprocess, 7.9ms inference, 23.3ms postprocess per image at shape (1, 3, 640, 640)
0%| | 0/3 [00:00<?, ?it/s]
33%|███▎ | 1/3 [00:01<00:03, 1.82s/it]
67%|██████▋ | 2/3 [00:03<00:01, 1.46s/it]
100%|██████████| 3/3 [00:03<00:00, 1.03it/s]
100%|██████████| 3/3 [00:03<00:00, 1.14s/it]
Decoding latents in cuda:0...
done in 0.81s
Move latents to cpu...
done in 0.0s
0: 640x640 1 face, 7.8ms
Speed: 3.0ms preprocess, 7.8ms inference, 1.4ms postprocess per image at shape (1, 3, 640, 640)
0%| | 0/3 [00:00<?, ?it/s]
33%|███▎ | 1/3 [00:01<00:03, 1.66s/it]
67%|██████▋ | 2/3 [00:02<00:01, 1.40s/it]
100%|██████████| 3/3 [00:03<00:00, 1.06it/s]
100%|██████████| 3/3 [00:03<00:00, 1.09s/it]
Decoding latents in cuda:0...
done in 0.81s
Move latents to cpu...
done in 0.0s
0: 640x640 1 face, 7.6ms
Speed: 3.0ms preprocess, 7.6ms inference, 1.4ms postprocess per image at shape (1, 3, 640, 640)
0%| | 0/3 [00:00<?, ?it/s]
33%|███▎ | 1/3 [00:01<00:03, 1.67s/it]
67%|██████▋ | 2/3 [00:02<00:01, 1.39s/it]
100%|██████████| 3/3 [00:03<00:00, 1.07it/s]
100%|██████████| 3/3 [00:03<00:00, 1.09s/it]
Decoding latents in cuda:0...
done in 0.81s
Move latents to cpu...
done in 0.0s
Uploading outputs...
Finished.
This example was created by evevalentine2017
Finished in 49.6 seconds
Setting up the model...
Preparing inputs...
Processing...
Full prompt: photograph, funny, the terminator in tutu looking at viewer, riding on a unicycle holding a big balloon made of flowers, stunning details, 8k, raw photo, 8k uhd, film grain, unreal engine 5, ray tracing, dynamic, Nikon d850, Depth of field 270mm, Amaro, Golden ratio, <lora:TLS:0.5>
Full negative prompt: CGI, Unreal, Airbrushed, Digital, dark, oversaturated, humans
0%| | 0/5 [00:00<?, ?it/s]
20%|██ | 1/5 [00:05<00:21, 5.36s/it]
40%|████ | 2/5 [00:10<00:16, 5.33s/it]
60%|██████ | 3/5 [00:15<00:10, 5.30s/it]
80%|████████ | 4/5 [00:19<00:04, 4.78s/it]
100%|██████████| 5/5 [00:21<00:00, 3.54s/it]
100%|██████████| 5/5 [00:21<00:00, 4.25s/it]
Decoding latents in cuda:0...
done in 2.39s
Move latents to cpu...
done in 0.03s
0: 640x640 1 face, 7.9ms
Speed: 3.8ms preprocess, 7.9ms inference, 23.3ms postprocess per image at shape (1, 3, 640, 640)
0%| | 0/3 [00:00<?, ?it/s]
33%|███▎ | 1/3 [00:01<00:03, 1.82s/it]
67%|██████▋ | 2/3 [00:03<00:01, 1.46s/it]
100%|██████████| 3/3 [00:03<00:00, 1.03it/s]
100%|██████████| 3/3 [00:03<00:00, 1.14s/it]
Decoding latents in cuda:0...
done in 0.81s
Move latents to cpu...
done in 0.0s
0: 640x640 1 face, 7.8ms
Speed: 3.0ms preprocess, 7.8ms inference, 1.4ms postprocess per image at shape (1, 3, 640, 640)
0%| | 0/3 [00:00<?, ?it/s]
33%|███▎ | 1/3 [00:01<00:03, 1.66s/it]
67%|██████▋ | 2/3 [00:02<00:01, 1.40s/it]
100%|██████████| 3/3 [00:03<00:00, 1.06it/s]
100%|██████████| 3/3 [00:03<00:00, 1.09s/it]
Decoding latents in cuda:0...
done in 0.81s
Move latents to cpu...
done in 0.0s
0: 640x640 1 face, 7.6ms
Speed: 3.0ms preprocess, 7.6ms inference, 1.4ms postprocess per image at shape (1, 3, 640, 640)
0%| | 0/3 [00:00<?, ?it/s]
33%|███▎ | 1/3 [00:01<00:03, 1.67s/it]
67%|██████▋ | 2/3 [00:02<00:01, 1.39s/it]
100%|██████████| 3/3 [00:03<00:00, 1.07it/s]
100%|██████████| 3/3 [00:03<00:00, 1.09s/it]
Decoding latents in cuda:0...
done in 0.81s
Move latents to cpu...
done in 0.0s
Uploading outputs...
Finished.