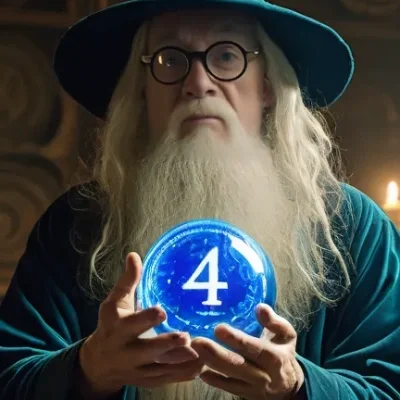
Version: lightning
Input
Output



This example was created by evevalentine2017
Finished in 23.2 seconds
Setting up the model...
Preparing inputs...
Processing...
Loading VAE weight: models/VAE/sdxl_vae.safetensors
Full prompt: Photorealism, photo of a floating island, 8K, colorful colors,
Full negative prompt: (worst quality, low quality, illustration, 3d, 2d, painting, cartoons, sketch), bad anatomy, tooth, open mouth, bad hand, bad fingers, watermark, deformed, distorted, disfigured, poorly drawn, (nude:2), nsfw, nsfw
0%| | 0/4 [00:00<?, ?it/s]
25%|██▌ | 1/4 [00:03<00:09, 3.29s/it]
50%|█████ | 2/4 [00:07<00:07, 3.71s/it]
75%|███████▌ | 3/4 [00:10<00:03, 3.32s/it]
100%|██████████| 4/4 [00:11<00:00, 2.39s/it]
100%|██████████| 4/4 [00:11<00:00, 2.78s/it]
Decoding latents in cuda:0...
done in 1.75s
Move latents to cpu...
done in 0.02s
0: 640x480 (no detections), 318.2ms
Speed: 4.9ms preprocess, 318.2ms inference, 2.8ms postprocess per image at shape (1, 3, 640, 480)
[-] ADetailer: nothing detected on image 1 with 1st settings.
0: 640x480 (no detections), 20.9ms
Speed: 4.6ms preprocess, 20.9ms inference, 2.2ms postprocess per image at shape (1, 3, 640, 480)
[-] ADetailer: nothing detected on image 2 with 1st settings.
0: 640x480 (no detections), 14.3ms
Speed: 3.2ms preprocess, 14.3ms inference, 1.3ms postprocess per image at shape (1, 3, 640, 480)
[-] ADetailer: nothing detected on image 3 with 1st settings.
Uploading outputs...
Finished.
This example was created by evevalentine2017
Finished in 23.2 seconds
Setting up the model...
Preparing inputs...
Processing...
Loading VAE weight: models/VAE/sdxl_vae.safetensors
Full prompt: Photorealism, photo of a floating island, 8K, colorful colors,
Full negative prompt: (worst quality, low quality, illustration, 3d, 2d, painting, cartoons, sketch), bad anatomy, tooth, open mouth, bad hand, bad fingers, watermark, deformed, distorted, disfigured, poorly drawn, (nude:2), nsfw, nsfw
0%| | 0/4 [00:00<?, ?it/s]
25%|██▌ | 1/4 [00:03<00:09, 3.29s/it]
50%|█████ | 2/4 [00:07<00:07, 3.71s/it]
75%|███████▌ | 3/4 [00:10<00:03, 3.32s/it]
100%|██████████| 4/4 [00:11<00:00, 2.39s/it]
100%|██████████| 4/4 [00:11<00:00, 2.78s/it]
Decoding latents in cuda:0...
done in 1.75s
Move latents to cpu...
done in 0.02s
0: 640x480 (no detections), 318.2ms
Speed: 4.9ms preprocess, 318.2ms inference, 2.8ms postprocess per image at shape (1, 3, 640, 480)
[-] ADetailer: nothing detected on image 1 with 1st settings.
0: 640x480 (no detections), 20.9ms
Speed: 4.6ms preprocess, 20.9ms inference, 2.2ms postprocess per image at shape (1, 3, 640, 480)
[-] ADetailer: nothing detected on image 2 with 1st settings.
0: 640x480 (no detections), 14.3ms
Speed: 3.2ms preprocess, 14.3ms inference, 1.3ms postprocess per image at shape (1, 3, 640, 480)
[-] ADetailer: nothing detected on image 3 with 1st settings.
Uploading outputs...
Finished.