Terminators with Juggernaut Turbo XL
Input
prompt
Specify things to see in the output
photograph, funny, the terminator in tutu looking at viewer, riding on a unicycle holding a big balloon made of flowers, stunning details, 8k, raw photo, 8k uhd, film grain, unreal engine 5, ray tracing, dynamic, Nikon d850, Depth of field 270mm, Amaro, Golden ratio
negative_prompt
Specify things to not see in the output
CGI, Unreal, Airbrushed, Digital, dark, oversaturated, humans
num_outputs
Number of output images
3
width
Output image width
1024
height
Output image height
1024
enhance_face_with_adetailer
Enhance face with adetailer
true
enhance_hands_with_adetailer
Enhance hands with adetailer
false
adetailer_denoising_strength
1: completely redraw face or hands / 0: no effect on output images
0.45
detail
Enhance/diminish detail while keeping the overall style/character
0
brightness
Adjust brightness
0.5
contrast
Adjust contrast
0
seed
Same seed with the same prompt generates the same image. Set as -1 to randomize output.
651144719
input_image
Base image that the output should be generated from. This is useful when you want to add some detail to input_image. For example, if prompt is "sunglasses" and input_image has a man, there is the man wearing sunglasses in the output.
input_image_redrawing_strength
How differ the output is from input_image. Used only when input_image is given.
0.55
reference_image
Image with which the output should share identity (e.g. face of a person or type of a dog)
reference_image_strength
Strength of applying reference_image. Used only when reference_image is given.
1
reference_pose_image
Image with a reference pose
reference_pose_strength
Strength of applying reference_pose_image. Used only when reference_pose_image is given.
1
reference_depth_image
Image with a reference depth
reference_depth_strength
Strength of applying reference_depth_image. Used only when reference_depth_image is given.
1
sampler
Sampler type
DPM++ SDE
samping_steps
Number of denoising steps
5
cfg_scale
Scale for classifier-free guidance
2
clip_skip
The number of last layers of CLIP network to skip
2
vae
Select VAE
None
lora_1
LoRA file. Apply by writing the following in prompt: <lora:FILE_NAME_WITHOUT_EXTENSION:MAGNITUDE>
lora_2
LoRA file. Apply by writing the following in prompt: <lora:FILE_NAME_WITHOUT_EXTENSION:MAGNITUDE>
lora_3
LoRA file. Apply by writing the following in prompt: <lora:FILE_NAME_WITHOUT_EXTENSION:MAGNITUDE>
embedding_1
Embedding file (textural inversion). Apply by writing the following in prompt or negative prompt: (FILE_NAME_WITHOUT_EXTENSION:MAGNITUDE)
embedding_2
Embedding file (textural inversion). Apply by writing the following in prompt or negative prompt: (FILE_NAME_WITHOUT_EXTENSION:MAGNITUDE)
embedding_3
Embedding file (textural inversion). Apply by writing the following in prompt or negative prompt: (FILE_NAME_WITHOUT_EXTENSION:MAGNITUDE)
disable_prompt_modification
Disable automatically adding suggested prompt modification. Built-in LoRAs and trigger words will remain.
false
Output


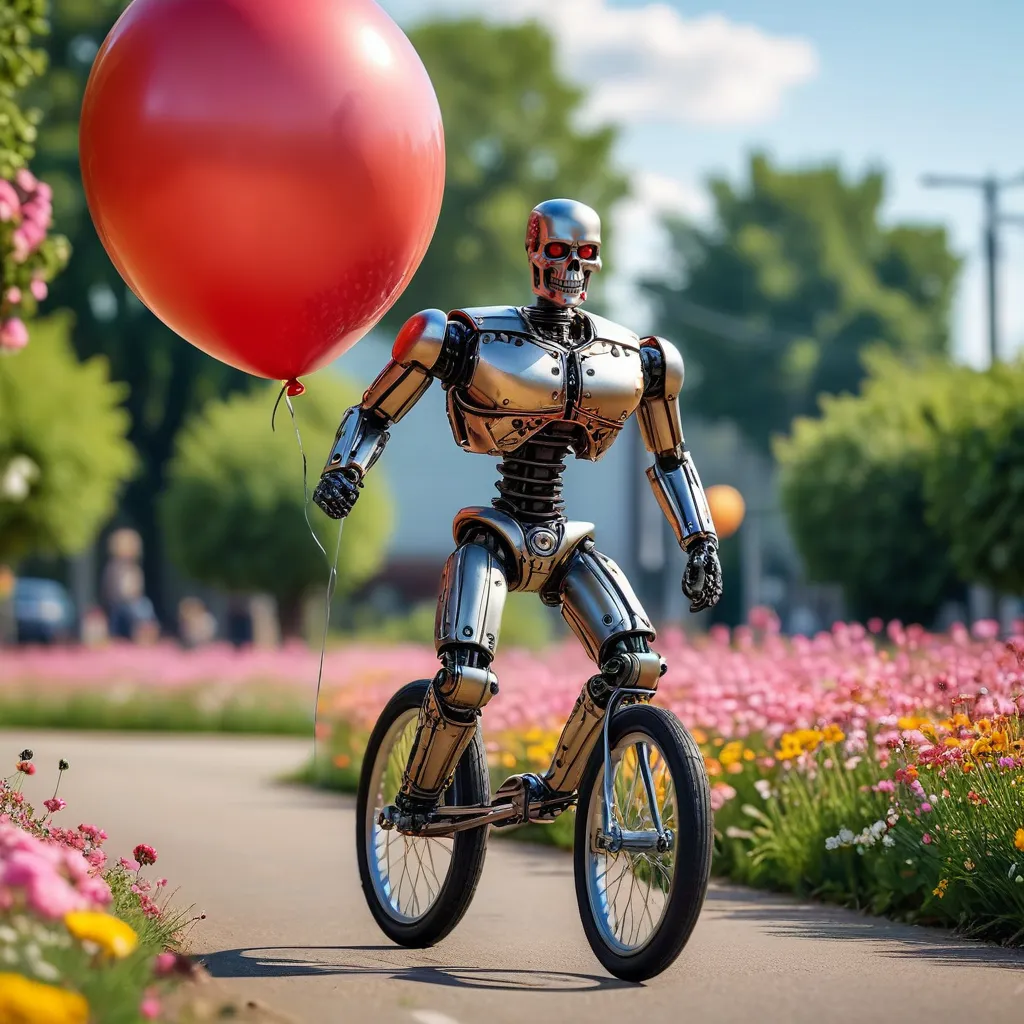
Finished in 49.6 seconds
prompt
Specify things to see in the output
photograph, funny, the terminator in tutu looking at viewer, riding on a unicycle holding a big balloon made of flowers, stunning details, 8k, raw photo, 8k uhd, film grain, unreal engine 5, ray tracing, dynamic, Nikon d850, Depth of field 270mm, Amaro, Golden ratio
negative_prompt
Specify things to not see in the output
CGI, Unreal, Airbrushed, Digital, dark, oversaturated, humans
num_outputs
Number of output images
3
width
Output image width
1024
height
Output image height
1024
enhance_face_with_adetailer
Enhance face with adetailer
true
enhance_hands_with_adetailer
Enhance hands with adetailer
false
adetailer_denoising_strength
1: completely redraw face or hands / 0: no effect on output images
0.45
detail
Enhance/diminish detail while keeping the overall style/character
0
brightness
Adjust brightness
0.5
contrast
Adjust contrast
0
seed
Same seed with the same prompt generates the same image. Set as -1 to randomize output.
651144719
input_image
Base image that the output should be generated from. This is useful when you want to add some detail to input_image. For example, if prompt is "sunglasses" and input_image has a man, there is the man wearing sunglasses in the output.
input_image_redrawing_strength
How differ the output is from input_image. Used only when input_image is given.
0.55
reference_image
Image with which the output should share identity (e.g. face of a person or type of a dog)
reference_image_strength
Strength of applying reference_image. Used only when reference_image is given.
1
reference_pose_image
Image with a reference pose
reference_pose_strength
Strength of applying reference_pose_image. Used only when reference_pose_image is given.
1
reference_depth_image
Image with a reference depth
reference_depth_strength
Strength of applying reference_depth_image. Used only when reference_depth_image is given.
1
sampler
Sampler type
DPM++ SDE
samping_steps
Number of denoising steps
5
cfg_scale
Scale for classifier-free guidance
2
clip_skip
The number of last layers of CLIP network to skip
2
vae
Select VAE
None
lora_1
LoRA file. Apply by writing the following in prompt: <lora:FILE_NAME_WITHOUT_EXTENSION:MAGNITUDE>
lora_2
LoRA file. Apply by writing the following in prompt: <lora:FILE_NAME_WITHOUT_EXTENSION:MAGNITUDE>
lora_3
LoRA file. Apply by writing the following in prompt: <lora:FILE_NAME_WITHOUT_EXTENSION:MAGNITUDE>
embedding_1
Embedding file (textural inversion). Apply by writing the following in prompt or negative prompt: (FILE_NAME_WITHOUT_EXTENSION:MAGNITUDE)
embedding_2
Embedding file (textural inversion). Apply by writing the following in prompt or negative prompt: (FILE_NAME_WITHOUT_EXTENSION:MAGNITUDE)
embedding_3
Embedding file (textural inversion). Apply by writing the following in prompt or negative prompt: (FILE_NAME_WITHOUT_EXTENSION:MAGNITUDE)
disable_prompt_modification
Disable automatically adding suggested prompt modification. Built-in LoRAs and trigger words will remain.
false
Finished in 49.6 seconds